Vorgehen
Anfang: jeder Knoten ist seine eigene Zusammenhangskomponente
- Sortiere alle edges im Graphen von billig zu teuer
- füge die kleinste Edge, die zwei ZHKs neu verbindet (keine cycles), hinzu
CodeExpert
In CodeExpert schauen, ob Arrays importiert ist, wenn ja, dann
Arrays.sort()
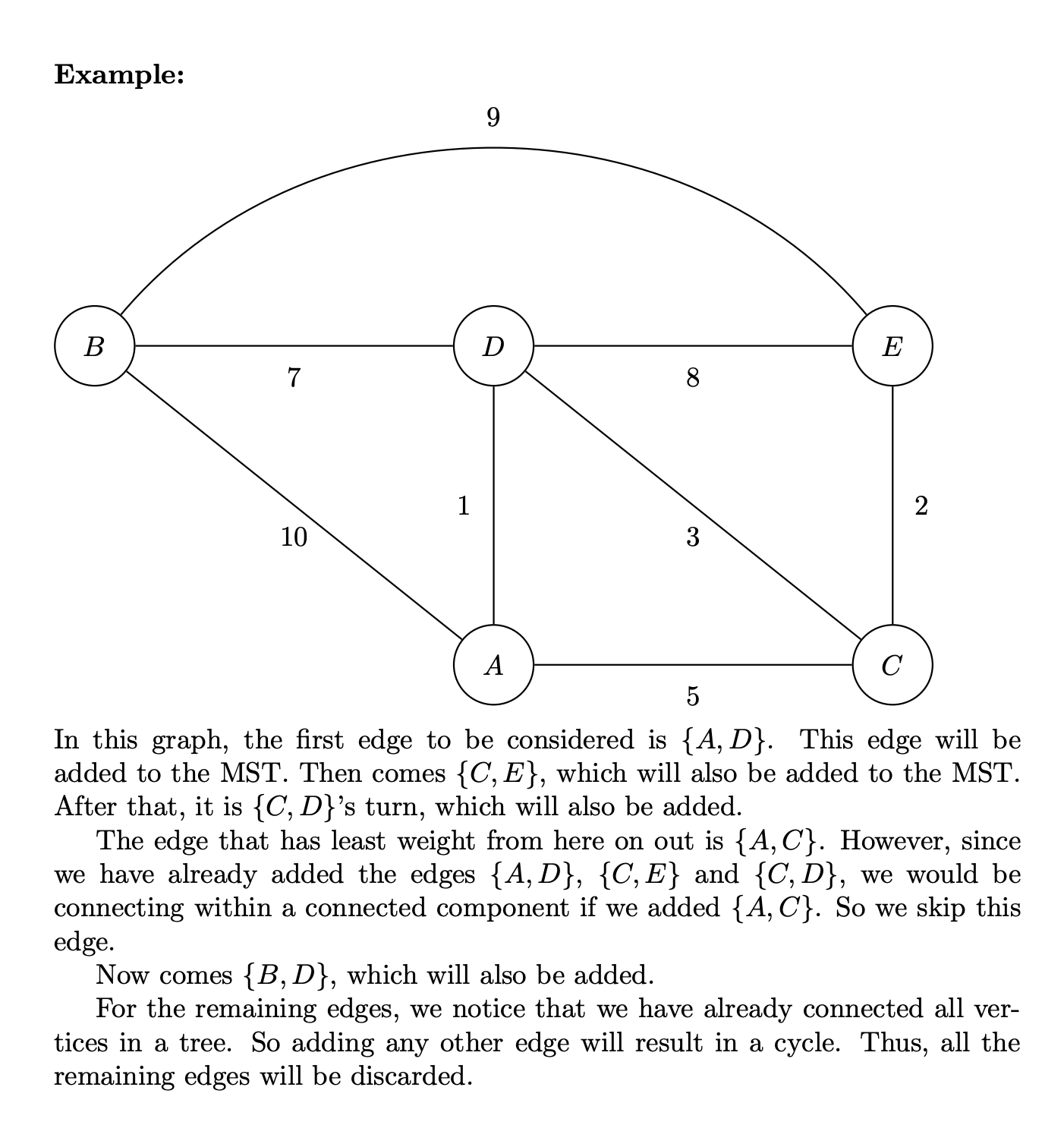
Pseudocode
Kruskal(edges):
U = unionFind(n)
sort(edges) // nach Gewicht sortieren
MST = leere Liste
for e in edges:
(u, v) = e
if not U.same(u, v):
MST.add(e)
U.union(u, v)
return MSTLaufzeit
Alle Kanten einzelnd durchzugehen und DFS laufen zu lassen (um ZHK zu überprüfen) wäre .
Mit Datenstruktur Union-Find .
Amotisierte Laufzeit (durchschnittlicher worst-case) von union
- wäre ja theoretisch , aber eine Situation wie ZHKs und ist unwahrscheinlich
- also im Schnitt
Asymptotisch gleich wie Boruvka und Prim da maximale Anzahl Kanten ,
Datenstruktur Union-Find
→ siehe UnionFind.java
- make
- same (sind u und v in der gleichen ZHK?)
- union (verbindet zwei ZHKs)
Pseudocode
class UnionFind
rep = Array[n]
// für jeden Knoten: speichert den "Repräsentanten"
// der verbundenen Komponente dieses Knotens
members = Array of LinkedLists[n]
// für jeden Repräsentanten: eine LinkedList,
// die alle Knoten seiner Komponente enthält
make(V): // V ist die Menge aller Knoten des Graphen
for each v in V:
rep[v] = v
// zu Beginn ist jeder Knoten seine eigene Komponente
same(u, v):
return rep[u] == rep[v]
// haben sie denselben Repräsentanten,
// liegen sie in derselben Komponente
union(u, v):
// ohne Einschränkung der Allgemeinheit nehmen wir an,
// dass die Komponente von u kleiner ist als die von v
for x in members[rep[u]]:
rep[x] = rep[v] // (1)
members[rep[v]].add(x) // (2)


